
Have you ever heard the saying “what you put in is what you get out”? That is especially true when we talk about artificial intelligence. AI systems learn from data by looking at thousands or even millions of examples. But what if someone secretly changes that data to mislead the AI? This is called data poisoning, and it is becoming a serious problem. It is like teaching a student with the wrong textbook on purpose, so they make mistakes later without knowing why. In this blog, we’ll look at data poisoning. We’ll discuss what it is, how it impacts AI, the ways it can occur, and what can be done to prevent it. Everything will be explained simply and clearly, even if you are just starting to learn about AI.
What is Data Poisoning?
Data poisoning is a type of adversarial attack where attackers tamper with the data used to train machine learning models. Unlike prompt injection or evasion attacks, it targets the model before deployment. The attacker adds misleading or harmful data to the training set to change how the model behaves.
How Does It Impact AI Models
Understanding the Impact of Data Poisoning on AI Models is crucial for organizations aiming to build secure and trustworthy machine learning systems. Here are the major ways it can affect AI systems:
1. Lower Accuracy
When a model learns from poisoned data, its predictions become less reliable. It may start making mistakes in tasks like diagnosing illnesses, spotting fraud, or giving financial advice.
2. Misclassification
In applications like image or voice recognition, poisoned data can cause the AI to label objects incorrectly. For example, a stop sign might be misread as a speed limit sign by a self-driving car, putting lives at risk.
3. Hidden Backdoors
Some attacks plant secret patterns during training so that the model behaves normally-until a specific trigger appears. At that moment, the model can be tricked into acting completely opposite to what is expected. This technique is often used in backdoor attacks.
4. Increased Vulnerability to Future Attacks
Poisoned models is often more fragile. Once compromised, they become easier to exploit with adversarial inputs, where just a tiny change in input can completely fool the system.
5. Biased or Unfair Decisions
If poisoned data contains intentional bias, the model can reflect that in its output. This is especially dangerous in areas like hiring, policing, or loan approvals, where fair treatment is crucial. A model might unintentionally favor or disfavor certain groups, creating discrimination.
6. Legal and Ethical Issues
Using a poisoned AI model can lead to serious legal and ethical concerns. A poorly trained AI in court or medical settings can cause real harm. This may lead to serious legal issues for companies or institutions that depend on these systems.
The Role of Data in Model Training
Data is the foundation of every machine learning model. Just like a student learns from books and exercises, AI models learn by studying examples which is known as training data. The quality of this data directly affects how well the model performs.
Training data can come from a wide variety of sources, such as:
- Online content like blogs, forums, and social media
- Sensor data from traffic cameras, GPS devices, and smart gadgets
- Public databases with environmental or demographic information
- Research datasets in fields like healthcare or education
- Business data, including customer records and sales trends
Clean, accurate data shapes how an AI model behaves. But if the data is flawed, containing errors, bias, or even intentional manipulation, then it can lead the model to learn the wrong patterns. This is where data poisoning becomes a serious threat. For example, if an attacker changes training labels like calling a horse a car, then the model may fail at critical tasks in the real world.
Protecting training data is just as important as designing the model itself. Without trustworthy input, even the most powerful AI can’t be relied upon.
Types of Data Poisoning
Data poisoning can be carried out in several ways, each designed to interfere with how an AI model learns and performs. Below are some of the most common attack types that threat actors use to compromise machine learning systems.

Figure 1: Types of Data Poisoning
1.Insider Attacks
Not all threats come from outside. Sometimes, individuals within an organization like employees or contractors intentionally modify the training data or algorithms. Because insiders often have deeper access, their changes can be subtle and very hard to trace.
2. Data Injection
In this type of attack, harmful data samples are quietly inserted into the training set. These samples are crafted to distort how the model behaves. For example, an attacker might feed false financial data into a loan prediction model, causing it to unfairly reject or approve applications.
3. Backdoor Attacks
A backdoor attack involves hiding a trigger inside the training data. When this secret pattern appears in real use, the model behaves exactly as the attacker wants. Otherwise, it seems to function normally.
4. Mislabeling Attacks
In mislabeling attacks, attackers deliberately assign the wrong labels to training examples. For instance, images of horses might be labeled as cars. When the AI trains on this data, it learns to associate the wrong features with each label. This can cause the model to make inaccurate predictions after deployment.
5. Machine Learning Supply Chain Attacks
AI systems often rely on third-party tools, code, and datasets. If these external sources are compromised, attackers can inject backdoors or poisoned data before the model is even built.
6. Data Manipulation
Here, the attacker tampers with the existing training data. This can include
- Adding incorrect records
- Removing useful or clean data
- Inserting confusing or adversarial examples
All of this can push the model to learn flawed logic or behave in unsafe ways.
7. Gradient Hijacking
In this advanced form of poisoning, attackers manipulate how the model adjusts its weight during training. By targeting the learning process itself, they can create long-term hidden weaknesses.
8. Subtle Drift Attacks
These attacks slowly change the data distribution over time. The changes are too small to notice one by one. Eventually, the AI adapts to incorrect trends without raising alerts.
Data Poisoning Symptoms
Detecting data poisoning is not always easy. Since AI models learn and adapt over time, small changes made by an attacker can slip through unnoticed. This is especially true if the attacker is someone within the organization. They know the systems, processes, and weaknesses inside and out.
To spot signs of a poisoning attack, know what attackers aim for. They often want to lower the model’s accuracy, change its behavior, or insert hidden biases. Below are some key symptoms to watch for
- Model Degradation – If the model’s performance suddenly drops without a clear reason, it may be learning from tampered or misleading data.
- Unexpected Outputs – When an AI system begins making strange or unexplained decisions, especially those that developers can’t trace back to training logic, this can point to hidden data corruption.
- More False Positives or Negatives – A sudden rise in errors-either flagging things it shouldn’t or missing what it should catch-can be a red flag that the model’s training base has been manipulated.
- Biased or Skewed Results – Models may begin to favor or disfavor certain outcomes, groups, or categories. This kind of behavior might indicate that attackers have added biased data into the training pool.
- Recent Security Incidents – If your organization has faced a cyber-attack or data breach recently, it might be a sign that someone has had the chance to alter your training data.
- Suspicious Employee Behavior – Employees showing unusual interest in training datasets or system security could be a warning sign. Insider threats often involve people with deeper access than external attackers.
Examples of Data Poisoning Attacks
Data poisoning attacks can take different forms, often depending on the attacker’s intent and the model’s purpose. Here are three impactful examples
1. Poisoning Autonomous Vehicle Training
Self-driving cars heavily rely on clean, accurate training data. If attackers inject tampered data, such as images that mislabel stop signs as yield signs then the vehicle could make dangerous decisions. Such poisoning can lead to serious real-world accidents.
2. Model Inversion Attacks
In this subtle yet harmful approach, attackers use the model’s outputs to reverse-engineer or infer sensitive data from the training set. Often carried out by insiders with access, this attack can expose personal or confidential information used during model training.
3. Backdoor Attacks in Image Recognition
As discussed earlier, backdoor attacks can subtly manipulate models by embedding secret triggers during training. One notable example is when researchers tricked an image classifier into identifying a toy turtle as a rifle, proving how even small, intentional changes in training data can compromise AI systems in high-stakes environments like surveillance or defense.
Direct vs. Indirect Data Poisoning Attacks
Data poisoning attacks are generally split into two types-direct and indirect, based on what the attacker is trying to achieve.
- Direct poisoning attacks focus on specific targets. The attacker subtly changes the training data so that the model misbehaves only for certain inputs. For example, a malware detection model might be tricked into treating a known virus as safe while still working fine for everything else.
- Indirect poisoning attacks aim to damage the model as a whole. Attackers inject random or misleading data into the training set, making the model less accurate overall. For instance, adding noisy images to an image classifier’s training data can reduce its performance across all predictions.
Data Poisoning vs. Prompt Injections
Although both data poisoning and prompt injection target AI systems, they do so at different stages and in unique ways. Understanding their differences is crucial to developing a strong defense strategy against adversarial threats in machine learning and generative AI.
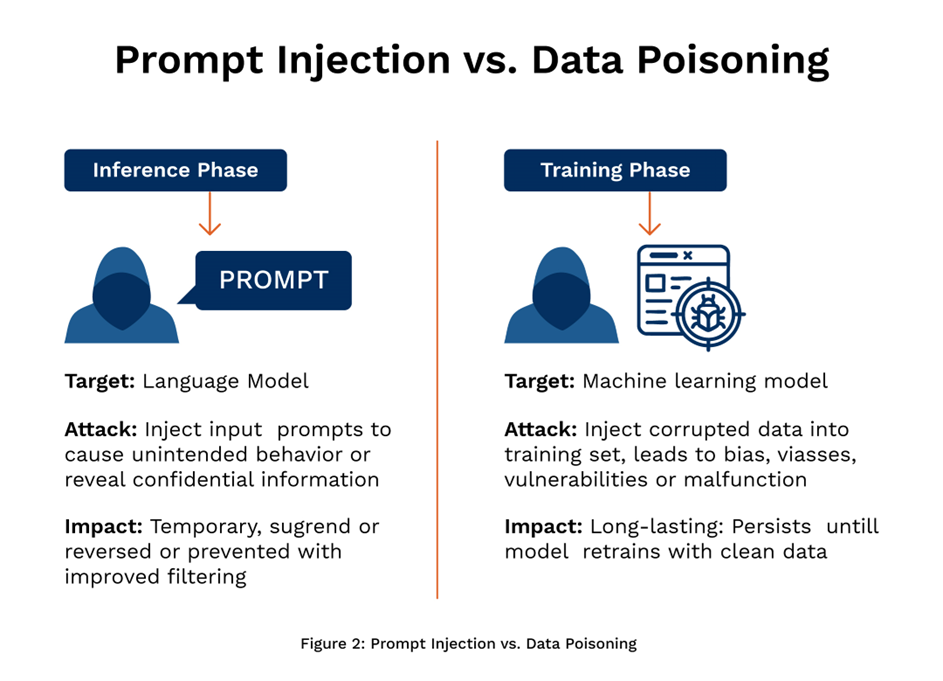
- Data poisoning affects an AI model during its training phase. Attackers sneak in corrupted or biased data into the training dataset, which misleads the model into learning incorrect patterns. This kind of manipulation can lead to inaccurate outputs, security flaws, and long-term degradation of the model’s performance. For instance, if a cybersecurity model is trained with mislabeled malware as safe software, it may fail to detect real threats later.
- Prompt injection, on the other hand, occurs after a model is already trained and deployed. It involves crafting malicious prompts that trick the model into performing unintended actions-like leaking sensitive data, spreading false information, or bypassing safety mechanisms. A classic case of this is when a chatbot is manipulated through indirect prompts embedded in web pages or messages, causing it to generate unsafe or biased responses.
Hackers may also combine both tactics for more destructive results. For example, a poisoned training dataset could prepare a model to behave in a certain way. Later, a prompt injection could trigger this behavior, allowing attackers to leak data, create backdoors, or manipulate decisions in real time.
Targeted vs. Nontargeted Attacks
Data poisoning attacks are often grouped into two major types based on the attacker’s goal i.e., targeted and nontargeted. Understanding the difference between them helps organizations design better detection strategies and defenses.
- Targeted Attacks
In targeted data poisoning, the attacker focuses on manipulating a model to behave in a very specific way. The intent is not to harm the entire system, but to subtly guide its output toward a particular goal. This might mean fooling a facial recognition system to confuse one person with another. It could also involve bypassing malware detection by disguising a dangerous file as safe.
These attacks are often precise, planned, and harder to detect. They usually involve backdoors or trigger patterns embedded in the training data. When the model encounters that specific trigger, it behaves exactly how the attacker wants.
- Nontargeted Attacks
Nontargeted attacks, on the other hand, aim to weaken the overall reliability of the AI model. Instead of attacking a single output or goal, the attacker floods the training data with noisy, misleading, or biased inputs. As a result, the model becomes less accurate, less stable, and more prone to errors across the board.
The goal is to lower the model’s overall performance. This makes it easier for future attacks or can make it useless in real-world situations.
While “direct/indirect” defines the attack method, “targeted/nontargeted” describes the attack’s goal.
AI Data Poisoning Tools
Both cybersecurity researchers and attackers have created advanced tools to study, exploit, or defend against data poisoning. These tools help simulate poisoning in academic settings or identify it in real-world applications.
- Nightshade – Nightshade is a data poisoning tool built to shield visual content from unauthorized use in AI model training. Created by academic researchers, it makes small changes to images. These changes are not seen by the human eye, but they can disrupt machine learning datasets. When poisoned visuals are added to models like Stable Diffusion, they lead to incorrect results or misinterpretations. Artists and content creators can use Nightshade to keep control of their digital assets in AI spaces.
- MetaPoison – MetaPoison takes a more sophisticated route. It uses meta-learning techniques to generate poisoned data that appears completely normal. This “clean label” strategy makes detection difficult, even with strict validation systems. These samples subtly distort a model’s behavior during real-world use, even after training on large datasets. MetaPoison works well in many cases, even in black-box settings like Google Cloud AutoML. This makes it a strong tool for examining the weaknesses of commercial AI systems.
Expert Tip (2025)
- Train models across decentralized devices using federated learning to limit centralized data exposure and make it harder for attackers to access and poison the training data.
- Add noise to the training process through differential privacy so that individual data points are hidden and attackers’ influence becomes much weaker.
- Use anomaly detection tools to find poisoned data samples early and set alerts for sudden shifts in model performance.
Conclusion
Data poisoning is a silent threat that can disrupt even well-trained AI models. Attackers can change training data. This lets them affect system behavior. Often, the changes go unnoticed until damage occurs. These attacks may not destroy models right away. Instead, they can slowly reduce accuracy, reliability, and trust over time.
To detect and prevent these threats, stay alert, and use smart data practices. Also, focus on security in development. From carefully selecting data sources to monitoring model performance, every step matters. In short, keeping AI safe starts with protecting the data it learns from.
FAQs
Data poisoning is when someone intentionally manipulates the training data used to teach a machine learning model. The goal is usually to sneak in bad information so that the model behaves in ways it’s not supposed to-whether by making wrong predictions, favoring certain inputs, or even failing completely.
It can seriously mess with how an AI system thinks and reacts. For example, it might start making poor decisions, misclassify data, or even contain hidden “backdoors” that attackers can exploit later. This kind of manipulation can lead to real-world consequences, especially in sensitive fields.
Not exactly, but they’re related. Think of data poisoning as one form of adversarial attack. While most adversarial attacks target the model after it’s trained, data poisoning goes deeper by targeting the training data itself to shape the model’s behavior from the beginning.
Yes, they can be vulnerable too-especially if they are trained on large-scale public data. If attackers manage to slip misleading or harmful content into the training sources, it can influence how the model responds later. That’s why data quality and vetting are so important.
Great question. Data poisoning is more of a long-term issue because it changes how the model learns and functions permanently. Prompt injection, on the other hand, is more immediate. It tricks the model at the moment of use by feeding it cleverly crafted inputs to alter responses.
It starts with securing the data pipeline. Companies should use reliable, verified sources, monitor for unusual patterns using anomaly detection tools, and have human experts review training data where possible. Building trust in the process helps reduce the chances of poisoning going unnoticed.
Yes, unfortunately. Because open datasets are available to the public, they can be manipulated by anyone who gains access. Without proper checks and validation mechanisms, these datasets can easily become targets for poisoning attempts.
Absolutely. Unsupervised models, which don’t rely on labeled data, are often used in clustering or feature learning. If attackers inject misleading data points, it can skew groupings, distort patterns, or lead to false insights, all without any obvious signs of foul play.
Industries like healthcare, finance, cybersecurity, and autonomous vehicles are especially at risk. That’s because decisions made by AI in these fields can directly impact people’s lives, security, and finances. A poisoned model in these areas could lead to serious harm.
Watch out for strange behaviors like sudden drops in accuracy, overfitting that doesn’t make sense, or weird reactions to specific inputs. If your model starts acting unpredictably, it might be a sign that something’s wrong with the data it learned from.
Yes, but only under certain conditions. If you’re able to identify and remove the poisoned data and then retrain the model using clean and verified data, you might be able to restore it. Otherwise, the poisoning effects could remain.
In some cases, partially. But if the poisoning has deeply influenced the model’s learning process, the safest route is often to start over with a clean dataset. That can be time-consuming, but it ensures the integrity of your model going forward.
There are several tools’ researchers use to study and simulate data poisoning attacks. Some well-known ones include TrojAI, BadNets, and PoisoningBench. These help developers understand vulnerabilities and test how models react under attack scenarios.
Not always. Sometimes poisoning happens unintentionally-like when poor-quality or mislabeled data is used during training. It can also occur due to human error, negligence, or even outdated data that no longer reflects reality.
Yes, and it already has started. New AI governance frameworks introduced in 2025 are beginning to require that high-risk AI systems use traceable and validated training data. This kind of regulation is a big step toward preventing data poisoning and improving overall AI safety.


